InnoDB study for an old school engineer - 1
들어가며
2000 년대 초반 시장을 쌈싸먹었던 Oracle 의 위상이 현재는 mysql 쪽으로 넘어온거 같습니다. 제가 처음으로 경험한 mysql 은 트렌젝션 특성도 지원하지 않던 3.x 버젼이었는데, 어느덧 시장을 다 재패하고 그 시절 Oracle 보다 더 큰 영향력을 발휘하고 있습니다. mysql 은 곁눈질로만 보고, 제대로 공부한 적이 없었는데 점점 나이는 먹어가고 위기감도 들어 공부를 시작해봅니다. innodb 를 중심으로 살펴볼 생각입니다.
InnoDB Physical Layout
메뉴얼을 보니 이 그림이 아주 멋져서 들고 왔습니다.
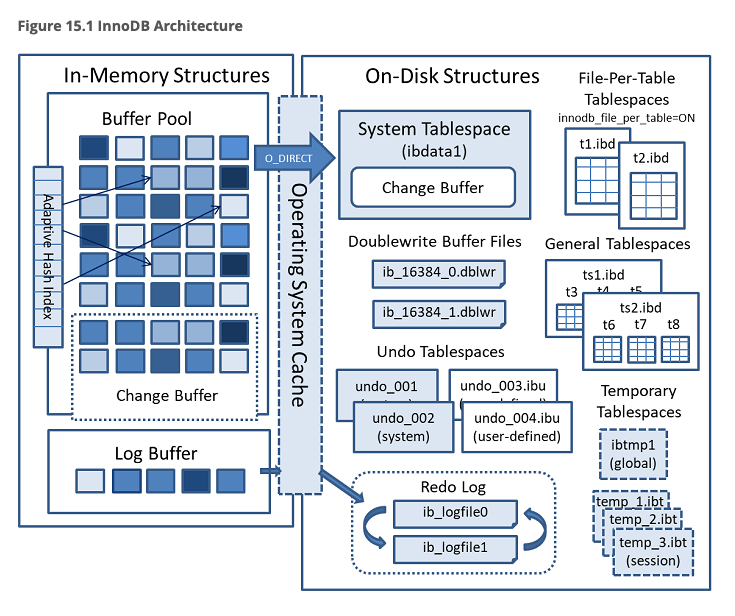
이 그림을 보고 흥미로운 점을 몇가지 찾아서 적어봅니다.
테이블이 저장되는 위치
보통 많은 디비들은 Tablespace -> Segment -> Extent - Page 구조의 물리적 계층으로 구분하여 공간 관리를 수행합니다. innodb 도 이러한 방식으로 구성되어있는데 흥미로웠던 점은 옵션(innodb_table_per_file) 을 통해서 테이블별 당 파일을 만들어서 사용할 수 있는 부분이 흥미로웠습니다. 이것도 테이블스페이스의 하나로 공식적인 용어는 “file-per-table tablespace” 라고 하더군요.
PostgreSQL 을 쓰면서 좋았던 점 하나는 테이블이 1GB 단위로 쪼개진 파일로 관리되기 때문에, DROP 을 수행하면 해당 파일에 unlink 가 일어나고, 그렇기 떄문에 파일 시스템으로 공간을 반납하는 것인데, file-per-table tablespace 를 쓰게 되면 동일한 효과를 누릴 수 있을 것 같습니다. Partitioned Tablespace 의 경우 역시 파티션당 파일이 생성되는 구조입니다. 잘 모르지만 저는 이 기능을 꼭 쓸꺼 같네요. 특히 백업과 복구 측면에서 테이블스페이스가 분리되어있다는 건 꽤 큰 장점을 가지니까요. 자세한 정보는 여기에 잘 정리되어있네요.
재밌는건 정책적으로 file-per-table tablespace 가 extend 되는 것은 픽스되어있습니다. ( 메뉴얼 상에는 4MB ) 만약 auto extend 로 인한 Jitter 가 신경 쓰인다면 수동으로 tablespace 를 만들어서 거기에 할당하는 방식으로 해야할것 같습니다. ( 사실 NVME 세상에서 큰 차이가 있을까 싶기는 합니다 )
file-per-table 설정으로 인한 물리적인 파일 위치는 데이터베이스 이름을 가진 디렉토리에 테이블명.ibd 라는 이름으로 저장됩니다.
별 설정안하고 yum 을 통해 설치해봤는데 이 값이 기본으로 켜져있네요.
Partial Write 에 대한 대비
InnoDB 에서 제공하는 Page 는 16K 이고, Sector 단위 보다 큽니다. Sector 크기로 write 하는 것은 atomicity 가 보장된다고 믿어 왔고, 그래서 Oracle 를 비롯한 많은 데이터베이스의 WAL Write 단위는 Sector 단위입니다. (512 또는 4096 bytes) ( NVME 에서는 Sector 단위 WRITE 에서 Atomictiy 를 보장하는 것이 스펙입니다.) 그래서 전원이 나가든 Kernel panic 이 발생했을 경우 Page Partial write 가 발생할 수 있고 이건 데이터가 깨질 수 있다는 것을 의미합니다.
PostgreSQL 과 Oracle 은 이러한 문제를 해결하기 위해서 Full Page Write 라는 기법을 사용했습니다. 이 방식은 간단히 말해 checkpoint 이후 첫번째로 변경되는 페이지는 전체 페이지를 WAL 에 기록한다는 기법입니다.
MySQL 는 조금 다른 방식으로 동작하는데, buffer pool 에서 dirty page 를 내려 쓸때 double write buffer 를 통해서 2중 쓰기로 진행하는 방식입니다. 만약 partial write 가 발생했어도 double write buffer 에는 제대로 된 페이지가 있을테니 이걸로 복구하겠다라는 전략입니다. 두번 쓴다고 해서 Double Write Buffer 라고 이름 지어진거 같습니다.
buf0dblwr.cc 에 해당 코드가 있는거 같은데, 잠깐 본 바로는 다음과 같이 동작하는 것 같습니다.
- Flush 할 Dirty Page들에 대한 리스트를 작성한다.
- 1 의 리스트를 double write buffer 에 쭉 내려쓴다. 마지막에 fsync() 를 호출해서 완벽하게 쓰여졌는지 검증한다.
- 이제 메모리의 내용을 데이터파일에 내려쓴다. 이때는 random i/o(pwrite) 가 발생
저는 Full Page Write 보다는 Double Write Buffer 방식이 최근 하드웨어 발전에는 더 맞는 거 같습니다. 이유라면 다음과 같은 것들이 있을 수 있습니다.
- Full Page Write 는 아무래도 WAL 에 부담을 주며 다른 DML Operation 에 영향을 미칠 수 밖에 없음. WAL 은 Global Resource 임
- 최신 innodb 에서는 Double Write Buffer 위치를 바꿀수 있게 되어있고, 이 파일을 다른 디바이스로 배치하여 I/O 컨텐션을 줄일 수 있음
- 최신 하드웨어 환경에서는 I/O 성능과 Latency 는 점점 좋아지고 있고, Double Write 로 손해보는 성능 수치는 점점 줄어들 것으로 보임
컨텐션에 고민을 많이 했다고 느끼는 부분은 버퍼별로 두개의 Double Write Buffer 를 유지했다는 것 입니다. 이는 Buffer 의 LRU List 와 Flush List 를 서로 다른 파일에 써서 Sequencial 쓰기의 장점을 극대화 시킨 것처럼 보입니다.
UNDO Tablespace
그림에는 User-Defined 라는 개념으로 약간 모호하게 적혀 있는 거 같은데, 사실 Undo Tablespace 는 기본적으로 Global 자원으로 보는게 맞을 것 같습니다. 사용자가 Undo Tablespace 를 추가한다고 해당 undo tablespace 의 사용을 사용자가 컨트롤 할 수 있는 것은 없습니다. R-R (Round-Robin) 방식으로 Transaction 이 언두를 선택해서 사용하게 되는 방식입니다.
undo 영역을 테이블스페이스 단위로 할당하고, 이를 DBA 가 ACTIVE / INACTIVE 로 변화시키면서 교체하는 방식으로 이해하면 될것 같습니다. CREATE UNDO TABLESPACE 라는 기능도 최신 기능인데 아무래도 I/O 분리를 위해서 사용자가 위치를 지정하게 만들수 있게 하기 위해서 만든거 같습니다.
PostgreSQL 은 언두 영역이라는 분리된 저장 요소라는 개념이 없고 실제 데이터가 저장되는 공간을 언두용도로 사용합니다. 모든 변경 연산은 새로운 레코드의 삽입으로 구현되고, Vacuum 이라는 작업을 통해서 반납하게 되는데 이 부분 때문에 PostgreSQL 은 대부분의 DDL 은 메타 정보를 고치는 정도로 이루어지게 됩니다. (add column with default 등) 이로 인해서 Bloating 이라고 불리는 현상이 발생하게 되는데 MySQL 은 Bloating 은 undo 영역에서만 발생하게 되므로 undo 영역만 관리해주면 실제 데이터 공간이 늘어나지는 않습니다. 단 DDL 수행시 직접 데이터를 업데이트해야하는 경우가 많아서 시간이 오래걸리고 부담이 될수 있겠네요.
제 생각은 자동으로 세팅해놓아도 별 문제가 없을 것 같고, 사용자가 정의하는 Undo Tablespace 는 I/O 를 분산하는 용도로 사용하면 될것 같습니다.
Change Buffer
이 부분도 꽤 궁금한 부분인데 쉽게 이해는 되지 않는 부분입니다. MySQL 에서 제공하는 인덱스 특성 및 구조를 좀 이해해야 알 수 있을 것 같습니다.
일단 여기까지.